《数据集成的未来!
-Airbyte》
时序数据是随时间不断产生的一系列数据,简单来说,就是带时间戳的数据。
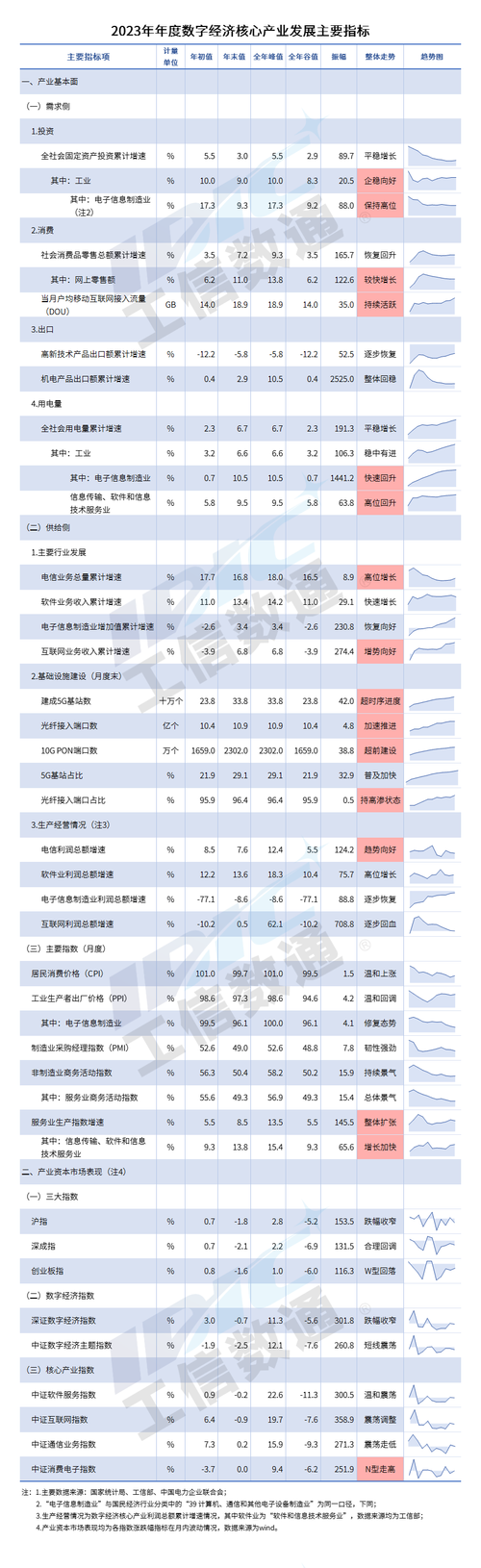
虽然其他数据库也可以在数据规模较小时一定程度上处理时间序列数据,但 TSDB可以更有效地处理随时间推移的数据摄取、压缩和聚合。以车联网场景为例,20000辆车,每个车60个指标,假设每秒采集一次,那么每秒将上报20000 60 = 1200000指标值,即120W数据指标值每秒,每个指标值为16字节(假设仅包括8字节时间戳和8字节的浮点数),则每小时将产生64G左右的数据。而实际上每个指标值还会附带标签等额外数据,实际需要存储空间会更大。
 软件开发")
时序数据主要由电力行业、化工行业、气象行业、地理信息等各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。
时序数据库特点
 软件开发")
数据写入的特点
写入平稳、持续、高并发高吞吐:时序数据的写入是比较平稳的,这点与应用数据不同,应用数据通常与应用的访问量成正比,而应用的访问量通常存在波峰波谷。时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。写多读少:时序数据上95%-99%的操作都是写操作,是典型的写多读少的数据。这与其数据特性相关,例如监控数据,你的监控项可能很多,但是你真正去读的可能比较少,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据。实时写入最近生成的数据,无更新:时序数据的写入是实时的,且每次写入都是最近生成的数据,这与其数据生成的特点相关,因为其数据生成是随着时间推进的,而新生成的数据会实时的进行写入。数据写入无更新,在时间这个维度上,随着时间的推进,每次数据都是新数据,不会存在旧数据的更新,不过不排除人为的对数据做订正。数据存储的特点
数据量大:拿监控数据来举例,如果我们采集的监控数据的时间间隔是1s,那一个监控项每天会产生86400个数据点,若有10000个监控项,则一天就会产生864000000个数据点。在物联网场景下,这个数字会更大。整个数据的规模,是TB甚至是PB级的。冷热分明:时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。具有时效性:时序数据具有时效性,数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。多精度数据存储:在查询的特点里提到时序数据出于存储成本和查询效率的考虑,会需要一个多精度的查询,同样也需要一个多精度数据的存储。今天
LinDB简介
LinDB 是一款高性能开源分布式时序数据库,支持多副本,具有良好的水平扩展能力,主要运行于物联网、工业互联网、IT 运维监控等领域。
LinDB 设计目标是高可用、高性能、为查询优化、弱依赖外部组件,适合中大型规模互联网企业使用,解决海量数据下的指标存储分析的痛点。
LinDB主要功能
高性能LinDB 参考了其他时序数据库里的最佳实践,并且在此基础上做了些优化。和 InfluxDB 中的 Continuous-Query 不一样,在创建数据库之后,LinDB支持根据指定的时间间隔自动对数据进行rollup。不仅如此,LinDB 在并行查询和计算分布式时序数据方面速度相当快。原生的多活支持LinDB 在设计阶段就是为了在饿了么的多活系统架构下工作的。LinDB的计算层(brokers)支持高效的跨机房聚合查询。高可用LinDB 使用 ETCD 集群以保证元数据的高可用和存储安全(也支持单机模式启动)。当出现故障时,多通道复制的WAL协议可以避免数据的不一致情况:1). 任一复制通道只有一名成员负责数据的权威性,因此避免了数据冲突;2). 数据可靠性保障:只要先前的leader数据并未丢失,当其重新上线时,这些数据便将被复制到其他的副本中;水平拓展性LinDB 使用了基于 Series(Tags) 的 sharding 策略,可以真正解决热点问题(另外也考验了系统设计的能力),简单的增加新的 broker 和 storage 节点即可实现水平拓展。Metric的治理能力为了保证系统的健壮性,LinDB 并不假设所有用户都已了解 metric 使用的最佳实践。因此,LinDB 提供了 metric 和 tag 粒度的限制能力,避免整体集群在部分用户错误的使用姿势下崩溃。界面截图
总结
Lindb,作为一款开源的分布式时序数据库,以其高效性能和简洁运维在大规模数据存储和快速查询方面表现突出。它通过依赖ETCD实现单机或分布式运行,支持分布式集群和多副本,确保数据高可用性。同时,Lindb的跨数据中心操作和最终一致性模型增强了其数据处理能力。尽管如此,Lindb在数据一致性、故障恢复、安全性和性能优化等方面可能面临挑战。潜在的解决方案包括改进数据同步、增强故障转移策略、定期更新安全补丁以及利用AI技术进行性能调优。
开源地址:https://github.com/lindb/lindb