文章目录
[+]
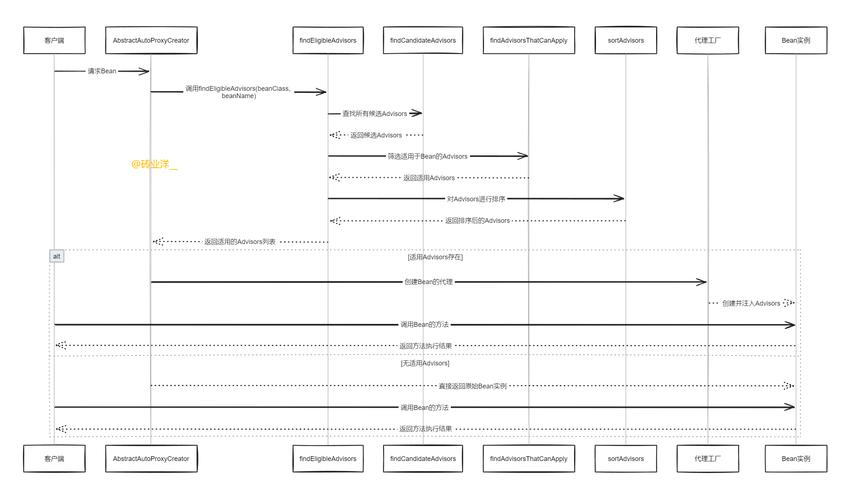
如果将所有参数锁定在Θ中,然后将其克隆为可训练的副本Θc。复制的Θc使用外部条件向量c进行训练。在本文中,称原始参数和新参数为“锁定副本”和“可训练副本”。制作这样的副本而不是直接训练原始权重的动机是:避免数据集较小时的过拟合,并保持从数十亿张图像中学习到的大型模型的能力。神经网络模块由一种称为“零卷积”的独特类型的卷积层连接,即1×1卷积层,权重和偏差都用零初始化。将零卷积运算表示为Z(·;·),使用参数{Θz1,Θz2}的两个实例组成ControlNet结构:
其中yc成为该神经网络模块的输出。因为零卷积层的权值和偏差都初始化为零,所以在第一个训练步骤中,有:
这可以转换为yc = y表明,在第一个训练步骤中,神经网络块的可训练副本和锁定副本的所有输入和输出都与它们的状态一致,就像ControlNet不存在一样。换句话说,当一个ControlNet应用于一些神经网络块时,在进行任何优化之前,它不会对深层神经特征造成任何影响。任何神经网络块的能力、功能和结果质量都得到了完美的保留,任何进一步的优化都将变得像微调一样快(与从零开始训练这些层相比)。下面简单地推导零卷积层的梯度计算。考虑权值W和偏差B的1 × 1卷积层,在任意空间位置p和通道索引i处,给定输入特征i∈h×w×c,正向通过可写成 软件开发")
(图片来自网络侵删)
 软件开发")
(图片来自网络侵删)
设置中,采样器为DDIM。默认使用20个步骤,三种类型的prompt来测试模型:
(1)No prompt:使用空字符串“”作为prompt。
(2)Default prompt:由于Stable diffusion本质上是用prompt训练的,空字符串可能是模型的一个意外输入,如果没有提供prompt,SD倾向于生成随机纹理。更好的设置是使用无意义的prompt,如“一张图片”、“一张漂亮的图片”、“一张专业的图片”等。在设置中,使用“专业、详细、高质量的图像”作为默认prompt。
(3)Automatic prompt:为了测试全自动流程最好的效果,还使用自动图像caption方法(如BLIP)。使用“Default prompt”模式获得的结果生成prompt,再次使用生成的prompt进行扩散生成。
(4)User prompt:用户给出prompt。
实现提出几种基于不同图像条件输入的方式,以控制生成。Canny边缘图。使用Canny边缘检测,用随机阈值从互联网上获得3M的边缘-图像-caption数据对。该模型使用Nvidia A100 80G进行600个gpu小时的训练。使用的基础模型是Stable Diffusion 1.5。此外,对上述Canny边缘数据集按图像分辨率进行排序,并采样1k、10k、50k、500k样本的子集。使用相同的实验设置来测试数据集规模的影响。Hough线图。使用基于深度学习的Hough变换方法对Places2数据集检测线图,并且使用BLIP生成caption。由此,得到了600k对的边缘-图像-caption。使用前面的Canny模型作为初始化checkpoint,并使用Nvidia A100 80G用150个gpu小时训练。HED边界检测。从互联网上获取3M的边缘-图像-caption的数据对,使用Nvidia A100 80G进行300个gpu小时训练。基础模型是Stable Diffusion 1.5。用户草图。结合HED边界检测和一组强数据增强(随机阈值、随机屏蔽涂鸦、随机形态变换、随机非极大抑制),从图像中合成人类涂鸦。从互联网上获得了50万对的涂鸦图像-caption数据对。使用前面的Canny模型作为初始化checkpoint,并使用Nvidia A100 80G用150个gpu小时训练。人体姿势(Openpifpaf)。使用基于学习的姿势估计方法来从互联网上“找到”人类,使用一个简单的规则:含有人类的图像必须有至少30%的全身关键点被检测到。获得了80k个姿势-图像-caption数据对。请注意,直接使用人体骨骼的可视化姿态图像作为训练条件。在Nvidia RTX 3090TI上使用400个gpu小时进行训练。基础模型是Stable Diffusion 1.5。人体姿势(Openpose)。使用基于学习的姿态估计方法在上面的Openpifpaf设置中使用相同的规则从互联网上找到人类。获得了200k个姿势-图像-caption数据对。直接使用人体骨骼的可视化姿态图像作为训练条件。使用Nvidia A100 80G进行300个gpu小时的训练,其他设置与上面的Openpifpaf相同。语义分割(COCO)。由BLIP对COCO-stuff数据集生成caption,获得了164K分割-图像-caption数据对。该模型在Nvidia RTX 3090TI上使用400个gpu小时进行训练。基础模型是Stable Diffusion 1.5。语义分割(ADE20K)。由BLIP对ADE20K数据集生成caption,获得了164K分割-图像-caption数据对。该模型在Nvidia A100 80G上使用200个gpu小时进行训练。基础模型是Stable Diffusion 1.5。深度(大尺度)。使用Midas从互联网上获取3M的深度-图像-caption数据对。使用Nvidia A100 80G进行500 gpu小时的训练。基础模型是Stable Diffusion 1.5。深度(小尺度)。对上述深度数据集的图像分辨率进行排序,采样200k的子集,用于训练模型所需的最小数据集大小。卡通线图提取方法。从网络上的卡通插图中提取线描。通过对受欢迎程度的卡通图像进行排序,得到了前1M的素描-卡通-caption数据对,使用Nvidia A100 80G进行300个gpu小时的训练。基础模型是Waifu Diffusion。本文转载于:CV技术指南
侵权联系删除